

前言
作为一名前端工程师,每天的清晨,你走进公司的大门,回味着前台妹子的笑容,摘下耳机,泡上一杯茶,打开 Terminal 进入对应的项目目录下,然后 npm run start / dev 或者 yarn start / dev 就开始了一天的工作。
当你需要进行时间的转换只需要使用 dayjs 或者 momentjs , 当你需要封装 http 请求的时候,你可以用 fetch 或者 axios , 当你需要做数据处理的时候,你可能会用 lodash 或者 underscore 。
不知道你有没有意识到,对于今天的我们而言,这些工具包让开发效率得到了巨大的提升,但是这一切是从什么开始的呢?
这些就要从 Modular design (模块化设计) 说起:
Modular design (模块化设计)
在我刚接触前端的时候,经常听说 Modular design (模块化设计) 这样的术语,面试时也会经常被问到,“聊聊前端的模块化”这样的问题,或许很多人都可以说出几个熟悉的名词,甚至是他们之间的区别:
- IIFE [Immediately Invoked Function Expression]
- Common.js
- AMD
- CMD
- ES6 Module
但就像你阅读一个项目的源码一样,如果从第一个 commit 开始研究,那么你能收获的或许不仅仅是,知道他们有什么区别,更重要的是,能够知道在此之前的历史中,是什么样的原因,导致了区别于旧的规范而产生的新规范,并且基于这些,或许你能够从中体会到这些改变意味着什么,甚至在将来的某个时刻,你也能成为这规则的制定者之一。
所以让我们回到十年前,来看看是怎么实现模块化设计的:
IIFE
IIFE 是 Immediately Invoked Function Expression 的缩写,作为一个基础知识,很多人可能都已经知道 IIFE 是怎么回事,(如果你已经掌握了 IIFE,可以跳过这节阅读后面的内容) 但这里我们仍旧会解释一下,它是怎么来的,因为在后面我们还会再次提到它:
最开始,我们对于模块区分的概念,可能是从文件的区分开始的,在一个简易的项目中,编程的习惯是通过一个 HTML 文件加上若干个 JavaScript 文件来区分不同的模块,就像这样:
我们可以通过这样一个简单的项目来说明,来看看每个文件里面的内容:
demo.html
这个文件,只是简单的引入了其他的几个 JavaScript 文件:
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>demo</title>
</head>
<script src="main.js"></script>
<script src="header.js"></script>
<script src="footer.js"></script>
<body></body>
</html>
其他三个 JavaScript 文件
在不同的 js 文件中我们定义了不同的变量,分别对应文件名:
var header = '这是一条顶部信息' //header.js
var main_message = '这是一条内容信息' //main.js
var main_error = '这是一条错误信息' //main.js
var footer = '这是一条底部信息' //footer.js
像这样通过不同的文件来声明变量的方式,实际上无法将这些变量区分开来。
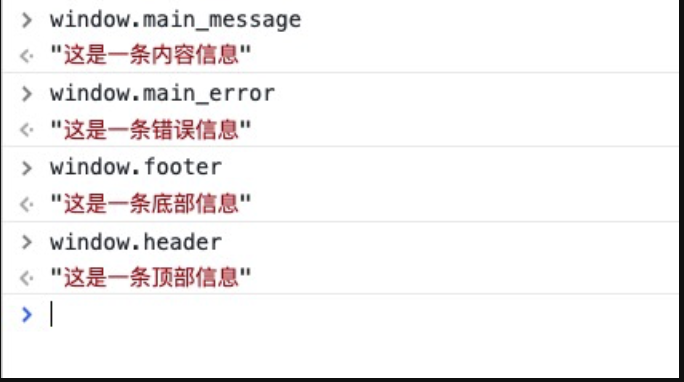
它们都绑定在全局的 window / Global(node 环境下的全局变量) 对象上,尝试去打印验证一下:
这简直就是一场噩梦,你可能没有意识到这会导致什么严重的结果,我们试着在 footer.js 中对 header 变量进行赋值操作,让我们在末尾加上这样一行代码:
header = 'nothing'
打印后你就会发现, window.header 的已经被更改了:

试想一下,你永远无法预料在什么时候什么地点无意中就改掉了之前定义的某个变量,如果这是在一个团队中,这是一件多么可怕的事情。
Okay,现在我们知道,仅仅通过不同的文件,我们无法做到将这些变量分开,因为它们都被绑在了同一个 window 变量上。
但是更重要的是,怎么去解决呢?我们都知道,在 JavaScript 中,函数拥有自己的作用域 的,也就是说,如果我们可以用一个函数将这些变量包裹起来,那这些变量就不会直接被声明在全局变量 window 上了:
所以现在 main.js 的内容会被修改成这样:
function mainWarraper() {
var main_message = '这是一条内容信息' //main.js
var main_error = '这是一条错误信息' //main.js
console.log('error:', main_error)
}
mainWarraper()
为了确保我们定义在函数 mainWarraper 的内容会被执行,所以我们必须在这里执行 mainWarraper() 本身,现在我们在 window 里面找不到 main_message 和 main_error 了,因为它们被隐藏在了 mainWarraper 中,但是 mainWarraper 仍旧污染了我们的 window:

这个方案还不够完美,怎么改进呢?
答案就是我们要说的 IIFE 我们可以定义一个 立即执行的匿名函数 来解决这个问题:
(function() {
var main_message = '这是一条内容信息' //main.js
var main_error = '这是一条错误信息' //main.js
console.log('error:', main_error)
})()
因为是一个匿名的函数,执行完后很快就会被释放,这种机制不会污染全局对象。
虽然看起来有些麻烦,但它确实解决了我们将变量分离开来的需求,不是吗?然而在今天,几乎没有人会用这样方式来实现模块化编程。
后来又发生了什么呢?
CommonJS
在 2009 年的一个冬天, 一名来自 Mozilla 团队的的工程师 Kevin Dangoor 开始捣鼓了一个叫 ServerJS 的项目,他是这样描述的:
"What I’m describing here is not a technical problem. It’s a matter of people getting together and making a decision to step forward and start building up something bigger and cooler together."
"在这里我描述的不是一个技术问题。 这是一个关于大家齐心合力,做出决定向前迈进,并且开始一起建造一些更大更酷的东西的问题。"
这个项目在 2009 年的 8 月份更名为今日我们熟悉的 CommonJS 以显示 API 更广泛的适用性。我觉得那时他可能并没有料到,这一规则的制定会让整个前端发生翻天覆地的变化。
CommonJS 在 Wikipedia 中是这样描述的:
CommonJS is a project with the goal to establish conventions on module ecosystem for JavaScript outside of the web browser. The primary reason of its creation was a major lack of commonly accepted form of JavaScript scripts module units which could be reusable in environments different from that provided by a conventional web browser e.g. web server or native desktop applications which run JavaScript scripts.
CommonJS 是一个旨在 Web 浏览器之外,为 JavaScript 建立模块生态系统的约定的项目。 其创建的主要原因是缺乏普遍接受的 JavaScript 脚本模块单元形式,而这一形式可以让 JavaScript 在不同于传统网络浏览器提供的环境中重复使用,例如, 运行 JavaScript 脚本的 Web 服务器或本机桌面应用程序。
通过上面这些描述,相信你已经知道 CommonJS 是诞生于怎样的背景,但是这里所说的 CommonJS 是一套通用的规范,与之对应的有非常多不同的实现:
但是我们关注的是其中 Node.js 的实现部分。
Node.js Modules
这里不会解释
Node.js Modules的 API 基本用法,因为这些都可以通过阅读 官方文档 来了解,我们会讨论为什么会这样设计,以及大家比较难理解的点来展开。
在 Node.js 模块系统中,每个文件都被视为一个单独的模块,在一个Node.js 的模块中,本地的变量是私有的,而这个私有的实现,是通过把 Node.js 的模块包装在一个函数中,也就是 The module wrapper ,我们来看看,在 官方示例中 它长什么样:
(function(exports, require, module, __filename, __dirname) {
// Module code actually lives in here
// 实际上,模块内的代码被放在这里
});
是的,在模块内的代码被真正执行以前,实际上,这些代码都被包含在了一个这样的函数中。
如果你真正阅读了上一节中关于 IIFE 的内容,你会发现,其实核心思想是一样的,Node.js 对于模块私有化的实现也还是通过了一个函数。但是这有哪些不同呢?
虽然这里有 5 个参数,但是我们把它们先放在一边,然后尝试站在一个模块的角度来思考这样一个问题:作为一个模块,你希望自己具备什么样的能力呢?
- 暴露部分自己的方法或者变量的能力 :这是我存在的意义,因为,对于那些想使用我的人而言这是必须的。[
exports:导出对象,module:模块的引用] - 引入其他模块的能力:有的时候我也需要通过别人的帮助来实现一些功能,只把我的注意力放在我想做的事情(核心逻辑)上。[
require:引用方法] - 告诉别人我的物理位置:方便别人找到我,并且对我进行更新或者修改。[
__filename:绝对文件名,__dirname:目录路径]
Node.js Modules 中 require 的实现
为什么我们要了解 require 方法的实现呢?因为理解这一过程,我们可以更好地理解下面的几个问题:
- 当我们引入一个模块的时候,我们究竟做了怎样一件事情?
exports和module.exports有什么联系和区别?- 这样的方式有什么弊端?
在文档中,有简易版的 require 的实现:
function require( /* ... */ ) {
const module = {
exports: {}
};
((module, exports) => {
// Module code here. In this example, define a function.
// 模块代码在这里,在这个例子中,我们定义了一个函数
function someFunc() {}
exports = someFunc;
// At this point, exports is no longer a shortcut to module.exports, and
// this module will still export an empty default object.
// 当代码运行到这里时,exports 不再是 module.exports 的引用,并且当前的
// module 仍旧会导出一个空对象(就像上面声明的默认对象那样)
module.exports = someFunc;
// At this point, the module will now export someFunc, instead of the
// default object.
// 当代码运行到这时,当前 module 会导出 someFunc 而不是默认的对象
})(module, module.exports);
return module.exports;
}
回到刚刚提出的问题:
1. require 做了怎样一件事情?
require 相当于把被引用的 module 拷贝了一份到当前 module 中
2. exports 和 module.exports 的联系和区别?
代码中的注释以及 require 函数第一行默认值的声明,很清楚的阐述了, exports 和 module.exports 的区别和联系:
exports 是 module.exports 的引用。作为一个引用,如果我们修改它的值,实际上修改的是它对应的引用对象的值。
就如:
exports.a = 1
// 等同于
module.exports = {
a: 1
}
但是如果我们修改了 exports 引用的地址,对于它原来所引用的内容来说,没有任何影响,反而我们断开了这个引用于原来的地址之间的联系:
exports = {
a: 1
}
// 相当于
let other = {
a: 1
} //为了更加直观,我们这样声明了一个变量
exports = other
exports 从指向 module.exports 变为了 other 。
3. 弊端
CommonJS 这一标准的初衷是为了让 JavaScript 在多个环境下都实现模块化,但是 Node.js 中的实现依赖了 Node.js 的环境变量: module , exports , require , global ,浏览器没法用啊,所以后来出现了 Browserify 这样的实现,但是这并不是本文要讨论的内容,有兴趣的同学可以读读阮一峰老师的 这篇文章。
说完了服务端的模块化,接下来我们聊聊,在浏览器这一端的模块化,又经历了些什么呢?
RequireJS & AMD(Asynchronous Module Definition)
试想一下,假如我们现在是在浏览器环境下,使用类似于 Node.js Module 的方式来管理我们的模块(例如 Browserify ),会有什么样的问题呢?
因为我们已经了解了 require() 的实现,所以你会发现这其实是一个复制的过程,将被 require 的内容,赋值到一个 module 对象的属性上,然后返回这个对象的 exports 属性。
这样做会有什么问题呢?在我们还没有完成复制的时候,无法使用被引用的模块中的方法和属性。在服务端可能这不是一个问题(因为服务器的文件都是存放在本地,并且是有缓存的),但在浏览器环境下,这会导致阻塞,使得我们后面的步骤无法进行下去,还可能会执行一个未定义的方法而导致出错。
相对于服务端的模块化,浏览器环境下,模块化的标准必须满足一个新的需求:异步的模块管理
在这样的背景下,RequireJS 出现了,我们简单的了解一下它最核心的部分:
- 引入其他模块:
require() - 定义新的模块:
define()
官方文档中的使用的例子:
requirejs.config({
// 默认加载 js/lib 路径下的module ID
baseUrl: 'js/lib',
// 除去 module ID 以 "app" 开头的 module 会从 js/app 路径下加载。
// 关于 paths 的配置是与 baseURL 关联的,并且因为 paths 可能会是一个目录,
// 所以不要使用 .js 扩展名
paths: {
app: '../app'
}
});
// 开始主逻辑
requirejs(['jquery', 'canvas', 'app/sub'],
function($, canvas, sub) {
//jQuery, canvas 和 app/sub 模块已经被加载并且可以在这里使用了。
});
官方文档中的定义的例子:
// 简单的对象定义
define({
color: "black",
size: "unisize"
});
// 当你需要一些逻辑来做准备工作时可以这样定义:
define(function() {
//这里可以做一些准备工作
return {
color: "black",
size: "unisize"
}
});
// 依赖于某些模块来定义属于你自己的模块
define(["./cart", "./inventory"], function(cart, inventory) {
//通过返回一个对象来定义你自己的模块
return {
color: "blue",
size: "large",
addToCart: function() {
inventory.decrement(this);
cart.add(this);
}
}
});
优势
RequireJS 是基于 AMD 规范 实现的,那么相对于 Node.js 的 Module 它有什么优势呢?
- 以函数的形式返回模块的值,尤其是构造函数,可以更好的实现API 设计,Node 中通过 module.exports 来支持这个,但使用 "return function (){}" 会更清晰。 这意味着,我们不必通过处理 “module” 来实现 “module.exports”,它是一个更清晰的代码表达式。
- 动态代码加载(在AMD系统中通过require([],function(){})来完成)是一项基本要求。 CJS谈到了, 有一些建议,但没有完全囊括它。 Node 不支持这种需求,而是依赖于require('')的同步行为,这对于 Web 环境来说是不方便的。
- Loader 插件非常有用,在基于回调的编程中,这有助于避免使用常见的嵌套大括号缩进。
- 选择性地将一个模块映射到从另一个位置加载,很方便的地提供了用于测试的模拟对象。
- 每个模块最多只能有一个 IO 操作,而且应该是简洁的。 Web 浏览器不能容忍从多个 IO 中来查找模块。 这与现在 Node 中的多路径查找相对,并且避免使用 package.json 的 “main” 属性。 而只使用模块名称,基于项目位置来简单的映射到一个位置的模块名称,不需要详细配置的合理默认规则,但允许在必要时进行简单配置。
- 最好的是,如果有一个 "opt-in" 可以用来调用,以便旧的 JS 代码可以加入到新系统。
如果一个 JS 模块系统无法提供上述功能,那么与 AMD 及其相关 API 相比,它将在回调需求,加载器插件和基于路径的模块 ID 等方面处于明显的劣势。
新的问题
通过上面的语法说明,我们会发现一个很明显的问题,在使用 RequireJS 声明一个模块时,必须指定所有的依赖项 ,这些依赖项会被当做形参传到 factory 中,对于依赖的模块会提前执行(在 RequireJS 2.0 也可以选择延迟执行),这被称为:依赖前置。
这会带来什么问题呢?
加大了开发过程中的难度,无论是阅读之前的代码还是编写新的内容,也会出现这样的情况:引入的另一个模块中的内容是条件性执行的。
SeaJS & CMD(Common Module Definition)
针对 AMD 规范中可以优化的部分,CMD 规范 出现了,而 SeaJS 则作为它的具体实现之一,与 AMD 十分相似:
// AMD 的一个例子,当然这是一种极端的情况
define(["header", "main", "footer"], function(header, main, footer) {
if (xxx) {
header.setHeader('new-title')
}
if (xxx) {
main.setMain('new-content')
}
if (xxx) {
footer.setFooter('new-footer')
}
});
// 与之对应的 CMD 的写法
define(function(require, exports, module) {
if (xxx) {
var header = require('./header')
header.setHeader('new-title')
}
if (xxx) {
var main = require('./main')
main.setMain('new-content')
}
if (xxx) {
var footer = require('./footer')
footer.setFooter('new-footer')
}
});
我们可以很清楚的看到,CMD 规范中,只有当我们用到了某个外部模块的时候,它才会去引入,这回答了我们上一小节中遗留的问题,这也是它与 AMD 规范最大的不同点:CMD推崇依赖就近 + 延迟执行
仍然存在的问题
我们能够看到,按照 CMD 规范的依赖就近的规则定义一个模块,会导致模块的加载逻辑偏重,有时你并不知道当前模块具体依赖了哪些模块或者说这样的依赖关系并不直观。
而且对于 AMD 和 CMD 来说,都只是适用于浏览器端的规范,而 Node.js module 仅仅适用于服务端,都有各自的局限性。
ECMAScript6 Module
ECMAScript6 标准增加了 JavaScript 语言层面的模块体系定义,作为浏览器和服务器通用的模块解决方案它可以取代我们之前提到的 AMD , CMD , CommonJS 。(在此之前还有一个 UMD(Universal Module Definition)规范也适用于前后端,但是本文不讨论,有兴趣可以查看 UMD文档 )
关于 ES6 的 Module 相信大家每天的工作中都会用到,对于使用上有疑问可以看看 ES6 Module 入门,阮一峰,当然你也可以查看 TC39的官方文档
为什么要在标准中添加模块体系的定义呢?引用文档中的一句话:
"The goal for ECMAScript 6 modules was to create a format that both users of CommonJS and of AMD are happy with"
"ECMAScript 6 modules 的目标是创造一个让 CommonJS 和 AMD 用户都满意的格式"
它凭借什么做到这一点呢?
- 与 CommonJS 一样,具有紧凑的语法,对循环依赖以及单个 exports 的支持。
- 与 AMD 一样,直接支持异步加载和可配置模块加载。
除此之外,它还有更多的优势:
- 语法比CommonJS更紧凑。
- 结构可以静态分析(用于静态检查,优化等)。
- 对循环依赖的支持比 CommonJS 好。
注意这里的描述里出现了两个词 循环依赖 和 静态分析,我们在后面会深入讨论。首先我们来看看, TC39 的 官方文档 中定义的 ES6 modules 规范是什么。
深入 ES6 Module 规范
在 15.2.1.15 节 中,定义了 Abstract Module Records (抽象的模块记录) 的 Module Record Fields (模块记录字段) 和 Abstract Methods of Module Records (模块记录的抽象方法)
Module Record Fields 模块记录字段
| Field Name(字段名) | Value Type(值类型) | Meaning(含义) |
|---|---|---|
| [[Realm]] 域 | Realm Record | undefined |
| [[Environment]] 环境 | Lexical Environment | undefined |
| [[Namespace]] 命名空间 | Object | undefined |
| [[Evaluated]] 执行结束 | Boolean | Initially false, true if evaluation of this module has started. Remains true when evaluation completes, even if it is an abrupt completion初始值为 false 当模块开始执行时变成 true 并且持续到执行结束,哪怕是突然的终止(突然的终止,会有很多种原因,如果对原因感兴趣可以看下 这个回答) |
Abstract Methods of Module Records 模块记录的抽象方法
| Method 方法 | Purpose 目的 |
|---|---|
| GetExportedNames(exportStarSet) | Return a list of all names that are either directly or indirectly exported from this module.返回一个从此模块直接或间接导出的所有名称的列表。 |
| ResolveExport(exportName, resolveSet, exportStarSet) | Return the binding of a name exported by this modules. Bindings are represented by a Record of the form {[[module]]: Module Record, [[bindingName]]: String}.返回此模块导出的名称的绑定。 绑定由此形式的记录表示:{[[module]]: Module Record, [[bindingName]]: String} |
| ModuleDeclarationInstantiation() | Transitively resolve all module dependencies and create a module Environment Record for the module.传递性地解析所有模块依赖关系,并为模块创建一个环境记录 |
| ModuleEvaluation() | Do nothing if this module has already been evaluated. Otherwise, transitively evaluate all module dependences of this module and then evaluate this module.如果此模块已经被执行过,则不执行任何操作。 否则,传递执行此模块的所有模块依赖关系,然后执行此模块。ModuleDeclarationInstantiation must be completed prior to invoking this method.ModuleDeclarationInstantiation 必须在调用此方法之前完成 |
也就是说,一个最最基础的模块,至少应该包含上面这些字段,和方法。反复阅读后你会发现,其实这里只是告知了一个最基础的模块,应该包含某些功能的方法,或者定义了模块的格式,但是在我们具体实现的时候,就像原文中说的一样:
An implementation may parse a sourceText as a Module, analyze it for Early Error conditions, and instantiate it prior to the execution of the TopLevelModuleEvaluationJob for that sourceText.
实现可以是:将 sourceText 解析为模块,对其进行早期错误条件分析,并在执行TopLevelModuleEvaluationJob之前对其进行实例化。
An implementation may also resolve, pre-parse and pre-analyze, and pre-instantiate module dependencies of sourceText. However, the reporting of any errors detected by these actions must be deferred until the TopLevelModuleEvaluationJob is actually executed.
实现还可以是:解析,预解析和预分析,并预先实例化 sourceText 的模块依赖性。 但是,必须将这些操作检测到的任何错误,推迟到实际执行TopLevelModuleEvaluationJob 之后再报告出来。
通过这些我们只能得出一个结论,在具体实现的时候,只有第一步是固定的,也就是:
解析:如 ParseModule 这一节中所介绍的一样,首先会对模块的源代码进行语法错误检查。例如 early-errors,如果解析失败,让 body 报出一个或多个解析错误和/或早期错误。如果解析成功并且没有找到早期错误,则将 body 作为生成的解析树继续执行,最后返回一个 Source Text Module Records
那后面会发生什么呢?我们可以通过阅读具体实现的源码来分析。
从 babel-helper-module-transforms 来看 ES6 module 实现
Babel 作为 ES6 官方指定的编译器,在如今的前端开发中发挥着巨大的作用,它可以帮助我们将开发人员书写的 ES6 语法的代码转译为 ES5 的代码然后交给 JS 引擎去执行,这一行为让我们可以毫无顾忌的使用 ES6 给我们带来的方便。
这里我们就以 Babel 中 babel-helper-module-transforms 的具体实现,来看看它是如何实现 ES6 module 转换的步骤
在这里我不会逐行的去分析源码,而是从结构和调用上来看具体的逻辑
首先我们罗列一下这个文件中出现的所有方法(省略掉方法体和参数)
/**
* Perform all of the generic ES6 module rewriting needed to handle initial
* module processing. This function will rewrite the majority of the given
* program to reference the modules described by the returned metadata,
* and returns a list of statements for use when initializing the module.
* 执行处理初始化所需的所有通用ES6模块重写
* 模块处理。 这个函数将重写给定的大部分
* 程序引用返回的元数据描述的模块,
* 并返回初始化模块时使用的语句列表。
*/
export function rewriteModuleStatementsAndPrepareHeader() {
...
}
/**
* Flag a set of statements as hoisted above all else so that module init
* statements all run before user code.
* 将一组语句标记为高于其他所有语句,以便模块初始化
* 语句全部在用户代码之前运行。
*/
export function ensureStatementsHoisted() {
...
}
/**
* Given an expression for a standard import object, like "require('foo')",
* wrap it in a call to the interop helpers based on the type.
* 给定标准导入对象的表达式,如“require('foo')”,
* 根据类型将其包装在对 interop 助手的调用中。
*/
export function wrapInterop() {
...
}
/**
* Create the runtime initialization statements for a given requested source.
* These will initialize all of the runtime import/export logic that
* can't be handled statically by the statements created by
* 为给定的请求源创建运行时初始化语句。
* 这些将初始化所有运行时导入/导出逻辑
* 不能由创建的语句静态处理
* buildExportInitializationStatements().
*/
export function buildNamespaceInitStatements() {
...
}
/**
* Build an "__esModule" header statement setting the property on a given object.
* 构建一个“__esModule”头语句,在给定对象上设置属性
*/
function buildESModuleHeader() {
...
}
/**
* Create a re-export initialization loop for a specific imported namespace.
* 为特定导入的命名空间,创建 重新导出 初始化循环。
*/
function buildNamespaceReexport() {
...
}
/**
* Build a statement declaring a variable that contains all of the exported
* variable names in an object so they can easily be referenced from an
* export * from statement to check for conflicts.
* 构建一个声明,声明包含对象中所有导出变量名称的变量的语句,以便可以从export * from语句中轻松引用它们以检查冲突。
*/
function buildExportNameListDeclaration() {
...
}
/**
* Create a set of statements that will initialize all of the statically-known
* export names with their expected values.
* 创建一组将通过预期的值来初始化 所有静态已知的导出名的语句
*/
function buildExportInitializationStatements() {
...
}
/**
* Given a set of export names, create a set of nested assignments to
* initialize them all to a given expression.
* 给定一组 export names,创建一组嵌套分配将它们全部初始化为给定的表达式。
*/
function buildInitStatement() {
...
}
然后我们来看看他们的调用关系:
我们以 A -> B 的形式表示在 A 中调用了 B
buildNamespaceInitStatements:为给定的请求源创建运行时初始化语句。这些将初始化所有运行时导入/导出逻辑rewriteModuleStatementsAndPrepareHeader所有通用ES6模块重写, 以引用返回的元数据描述的模块。 ->buildExportInitializationStatements创建所有静态已知的名称的 exports ->buildInitStatement给定一组 export names,创建一组嵌套分配将它们全部初始化为给定的表达式。
所以总结一下,加上前面我们已知的第一步,其实后面的步骤分为两部分:
- 解析:首先会对模块的源代码进行语法错误检查。例如 early-errors,如果解析失败,让 body 报出一个或多个解析错误和/或早期错误。如果解析成功并且没有找到早期错误,则将 body 作为生成的解析树继续执行,最后返回一个 Source Text Module Records
- 初始化所有运行时导入/导出逻辑
- 以引用返回的元数据描述的模块,并且用一组 export names 将所有静态的 exports 初始化为指定的表达式。
到这里其实我们已经可以很清晰的知道,在 编译阶段 ,我们一段 ES6 module 中的代码经历了什么: ES6 module 源码 → Babel 转译 → 一段可以执行的代码 也就是说直到编译结束,其实我们模块内部的代码都只是被转换成了一段静态的代码,只有进入到运行时才会被执行。 这也就让 静态分析 有了可能。